
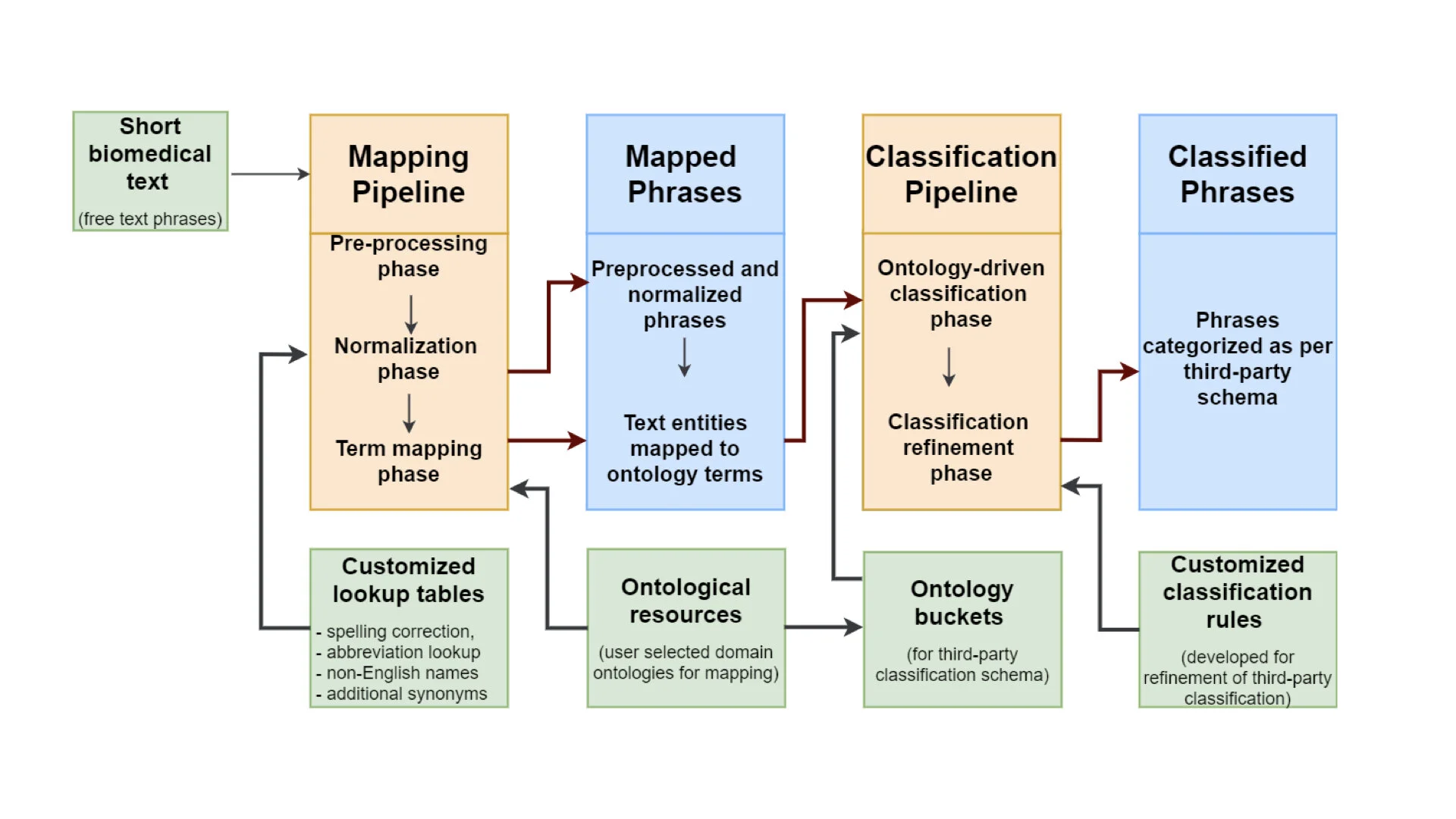
The initial focus of LexMapr development has been on providing a text-mining tool to clean up the short free-text biosample metadata that contained inconsistent punctuation, abbreviations and typos, and to map the identified entities to standard terms from ontologies. This blog is the second in a series on text-mining in CINECA. For the previous instalment "Uncovering metadata from semi-structured cohort data" please click here.
Read More